電腦能夠記住的任務就讓電腦來做吧,把腦容量留給更重要的任務
 為什麼要學習排程?
為什麼要學習排程?在客戶要求這個功能前其實我就把他的雛型完成了,因為我是一個懶人,同時也不是一個記性很好的人,如果每天都要在某個時間打開專案執行 yarn start 然後等數據跑完,這對我來說實在是一件很容易忘記且沒有效率的事情,我認為電腦可以做到事情那就交給電腦去做,所以接下來幾天就來跟大家分享我是如何偷懶使用排程的
 今日目標
今日目標1.1 測試官方程式
1.2 分析 api 架構
1.3 了解 cronTime 語法
1.4 範例
2.1 將主程式的函式crawler設定成外部函式,供排程呼叫
2.2 建立專門管控排程的程式:cron.js
2.3 調整package.json,建立專門跑排程的 scripts
這裡我們需要安裝一個套件 cron ,他可以在你指定的時間執行你希望他幫你做的事情,這是他的官方文檔,下面我會詳細介紹他的功能(因為我自己也很常使用XD)
yarn add cron
var CronJob = require('cron').CronJob;
var job = new CronJob('* * * * * *', function() {
console.log('You will see this message every second');
}, null, true, 'America/Los_Angeles');
job.start();
constructor(cronTime, onTick, onComplete, start, timezone, context, runOnInit, unrefTimeout)
秒:0-59
分鐘:0-59
小時:0-23
天:1-31
月份:0-11(1~12月,特別注意月份是從0開始)
星期幾:0-6(星期日~星期六,Sun~Sat)
* 全部
* * * * * *
10 * * * * *
10 30 22 * * *
- 時間區間
0 0 9-12 * * *
, 分隔符號,可以輸入多個數值
5,20,30 * * * * *
/ 間隔多少時間執行
* */3 * * * *
var CronJob = require('cron').CronJob;
new CronJob('10 * * * * *', function () {
const datetime = new Date();
console.log(datetime);
}, null, true);
var CronJob = require('cron').CronJob;
new CronJob('5,20,30 * * * * *', function () {
const datetime = new Date();
console.log(datetime);
}, null, true);
我們要調整三個檔案讓排程可以順利觸發爬蟲
crawler設定成外部函式,供排程呼叫require('dotenv').config();
const { initDrive } = require("./tools/initDrive.js");
const { crawlerFB } = require("./tools/crawlerFB.js");
const { crawlerIG } = require("./tools/crawlerIG.js");
const { updateGoogleSheets } = require("./tools/google_sheets");
exports.crawler = crawler; //讓其他程式在引入時可以使用這個函式
async function crawler () {
const driver = await initDrive();
if (!driver) {
return
}
const ig_result_array = await crawlerIG(driver)
const fb_result_array = await crawlerFB(driver)
driver.quit();
await updateGoogleSheets(ig_result_array, fb_result_array)
}
cron.js日後維護時比較了解每個參數的意義
const CronJob = require('cron').CronJob;
const { crawler } = require("../index.js");
new CronJob({
cronTime: process.env.CRONJOB_TIME,//請編輯.env檔填上自己的爬蟲時段喔
onTick: async function () {
console.log(`開始執行爬蟲排程作業: ${new Date()}`);
await crawler()
console.log('排程作業執行完畢!');
},
start: true,
timeZone: 'Asia/Taipei'
});
package.json,建立專門跑排程的 scripts針對 node 如何執行 js 指定 function 的指令寫法可以參考這篇文章
{
"name": "crawler",
"version": "0.0.1",
"description": "FB & IG 爬蟲30天鐵人文章",
"author": "dean lin",
"dependencies": {
"cron": "^1.8.2",
"dateformat": "^3.0.3",
"dotenv": "^8.2.0",
"googleapis": "59",
"selenium-webdriver": "^4.0.0-alpha.7"
},
"devDependencies": {},
"scripts": {
"start": "node -e 'require(\"./index\").crawler()'",
"win_start": "node -e \"require('./index').crawler()\"",
"cron":"node tools/cron.js"
},
"main": "index.js",
"license": "MIT"
}
 執行程式
執行程式yarn start
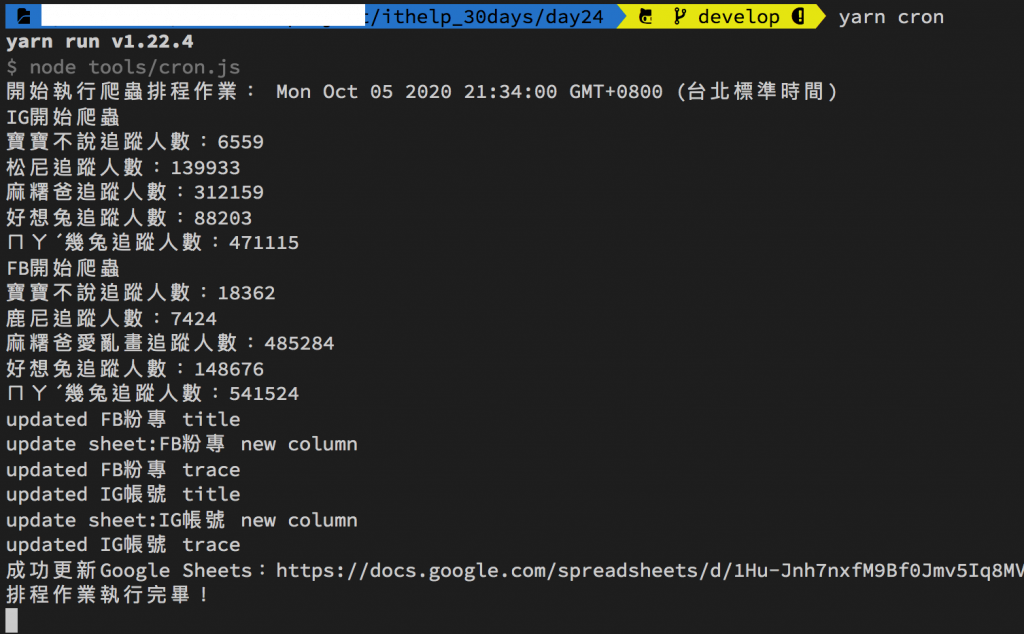
排程的程式會一直執行,所以你不會看到以往 Done in xxs 的訊息,如果想要中斷終端機(Terminal)執行的程式,可以用下面按鍵組合:
 參考資源
參考資源我在 Medium 平台 也分享了許多技術文章
❝ 主題涵蓋「MIS & DEVOPS、資料庫、前端、後端、MICROSFT 365、GOOGLE 雲端應用、自我修煉」希望可以幫助遇到相同問題、想自我成長的人。❞
在許多人的幫助下,本系列文章已出版成書,並添加了新的篇章與細節補充:
- 加入更多實務經驗,用完整的開發流程讓讀者了解專案每個階段要注意的事項
- 將爬蟲的步驟與技巧做更詳細的說明,讓讀者可以輕鬆入門
- 調整專案架構
- 優化爬蟲程式,以更廣的視角來擷取網頁資訊
- 增加資料驗證、錯誤通知等功能,讓爬蟲執行遇到問題時可以第一時間通知使用者
- 排程部分改用 node-schedule & pm2 的組合,讓讀者可以輕鬆管理專案程序並獲得更精確的 log 資訊
有興趣的朋友可以到天瓏書局選購,感謝大家的支持。
購書連結:https://www.tenlong.com.tw/products/9789864348008




